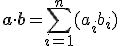Most kezdjük a program átnézését a kernellel.
Kelnelből adott véges számút fogunk indítani. Ez legyen mondjuk 32 blokk egyenként 256-256 szállal. Ez a legtöbb GPU-n elég sok párhuzamos szálat ad, hogy hatékony legyen a számítás.
Nezzül először, hogy mit is csinálnak a szálak.
Minden szál, amikor elindul elkezd összegezni, és kiszámítá egy részösszeget.
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int offset = gridDim.x * blockDim.x;
float result = 0.0f;
for (; tid < elementNum; tid += offset)
{
result += a[tid] * b[tid];
}
Itt gyakorlatilag minden szál meghatározza, hogy hanyadik pozíción áll a rácsban. Majd ettől az indextul elindulva összeszoroz egy elempárt, és az eredményt hozzáadja egy részösszeghez. Ezek után tovább lép annyi elemme, ahány szál van, és megismétli a folyamatot.
- Itt kell megyjegyezni, hogy a lépés méretének is fontos szerepe van a memória ideális kezelése érdekében. További információ az előadáson.
Ez azt eredményezi, hogy szálak jó nagy pélésekben lépkedve együttesen kiszámítják az összes részösszeget. Vagyis jelen esetben minden szálnál megvan a teljes eredmény egy kis része. Ezeket kellene összeadni a végeredmény megkapásához.
A szálak között adatokat nem tudunk átadni, ezért a GPU-n belül - jelen tudásunkkal - nem tudjuk a teljes összeget előállítani. A blokkon belül viszont tudunk szinkronizálni, tehát tudunk összegezni is, amit a következő kódrészlettel oldunk meg.
cache[threadIdx.x] = result;
__syncthreads();
int i = blockDim.x / 2;
int cacheIndex = threadIdx.x;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
ebben a kódban először minden szál kiírja a részeredményét a közös memória egy rekeszébe. Majd szinkronizálnak!
A szinkronizáció után iteratvín dolgozunk. Az első iterációban a szálaknak csak az első fele dolgozik. Azok a saját részeredményükhöz hozzáadnak egy részeredményt, amit a szálak második feléből állított elő valamelyik. Ezzel megfelezzük a részösszegek számát.
A következő iterációban már csak aszálak negyede dolgozik, és hozzáadja a saját részeredményéhez a második negyed részeredményeit, amivel megint megfelezzük a részösszegek számát. És így tovább.
Ezzel a módszerrel párhuzamosan logaritmikus iteráció számban (vagyis most 8 lépésben) előállítjuk a teljes részösszeget.
Ezzel minden blokkban marad egy részösszeg, amiket össze kellene adnunk, de nem tudunk. Viszont nem is kell. 32 blokk mellett az csak 31 összeadás, amit már a CPU is gyoran meg tud oldani. Ezért a megoldás, hogy a részeredményeket kiírjuk egy tömb egy-egy elemébe, és hagyjuk, hogy a CPU kezelje azokat.
if (threadIdx.x == 0)
partialC[blockIdx.x] = cache[0];
Itt persze blokkonként elég, ha egy-egy szál dolgozik. Ez legyen mondjuk az 1. indexű.