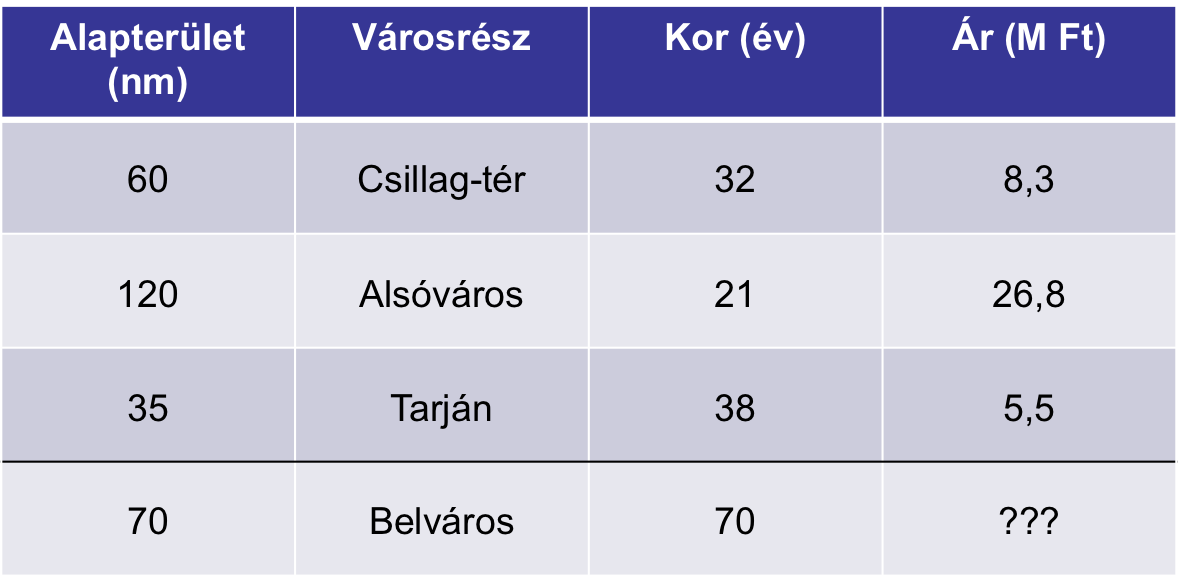
Regressziós feladat
Az eddigiekben elsősorban osztályozási feladatok gépi tanulási megoldásával foglalkoztunk. Ebben a leckében egy
másik felügyelt gépi tanulási feladattal ismerkedünk meg, a regresszióval. A regresszió is
felügyelt gépi tanulási feladat, azaz rendelkezésre áll egy tanító adatbázis, ami alapján egy modellt kell tanulnunk, ami utána korábban nem
látott egyedekre is képes predikálni. Azonban míg az osztályozási feladatnál a célváltozó egy osztály/kategória címke, addig a regressziónál a
célváltozó egy folytonos érték. Az egyedeket ugyanúgy jellemzőkkel írjuk le, mint az osztályozásnál, de más gépi tanulási megközelítésekre
van szükség ha folytons értéket akarunk predikálni/előrejelezni (forecast). Természetesen az egyedek típusa is tetszőleges lehet. Például szövegbányászatban
predikálni akarjuk, hogy egy szöveges vélemény az 1-10 skálán mennyire pozitív (product rating).
Kiértékelési metrikák a regressziós feladatnál
Mivel a regresszió is felügyelt gépi tanulási feladat, ezért a kiértékelés módszertana megegyezik az oszályozási feladatéval, azaz tanító és kiértékelő adatbázisra bontjuk a címkézett adathalmazunkat, a tanító adatbázison tanítunk egy modellt és az elkülönített kiértékelő adatbázison mérjük a modell pontosságát/teljesítményét.
Azonban a találati arány és pontosság+fedés kiértékelési metrikák nem értelmezhetőek folytonos célváltozó predikciójánál, a regressziós feladathoz speciális kiértékelési metrikát kell választanunk. A regressziós feladatoknál leggyakrabban használt kiértékelési metrika az átlagos négyzetes hiba (mean squared error, MSE). Legyen \(\vec{x}\) egy kiértékelő adatbázisbeli egyed jellemzővektora és \(r\) a hozzá tartozó ismert célváltozó érték. Jelöljük \(g(\vec{x})\)-vel egy regressziós modell predikcióját az \(\vec{x}\) jellemzővektorra (egy folytonos érték). Ekkor az \(N\) elemű kiértékelő adatbázison számított átlagos négyzetes hiba: \[ MSE = \frac{\sum\limits_{i=1}^N {( r_i - g(\vec{x}_i) )^2}}{N} \] Gyakran ennek négyzetgyök használják kiértékelési metrikának (root mean square error, RMSE): \( RMSE = \sqrt{MSE} \)
Gépi tanulási algoritmusok regresszióra
Számtalan gépi tanulási algoritmus létezik regresszió tanulására. A legtöbb osztályozó algoritmus kis átalakítással regressziós algoritmussá alakítható. Mi itt most áttekintjük, hogy a korábbi leckékben megismert osztályozó algoritmusok milyen módosítással használhatóak regressziós problémára.
Lineáris regresszió
Sőt a lineáris gépek alapvetően regressziót csinálnak, hiszen a \(g()\) diszkriminancia függvény egy folytonos értéket predikál amit utána osztályozási döntéssé alakítunk. Lineáris regresszió esetén egyetlen diszkriminancia függvényt tanulunk és annak kimenete lesz a predikciónk.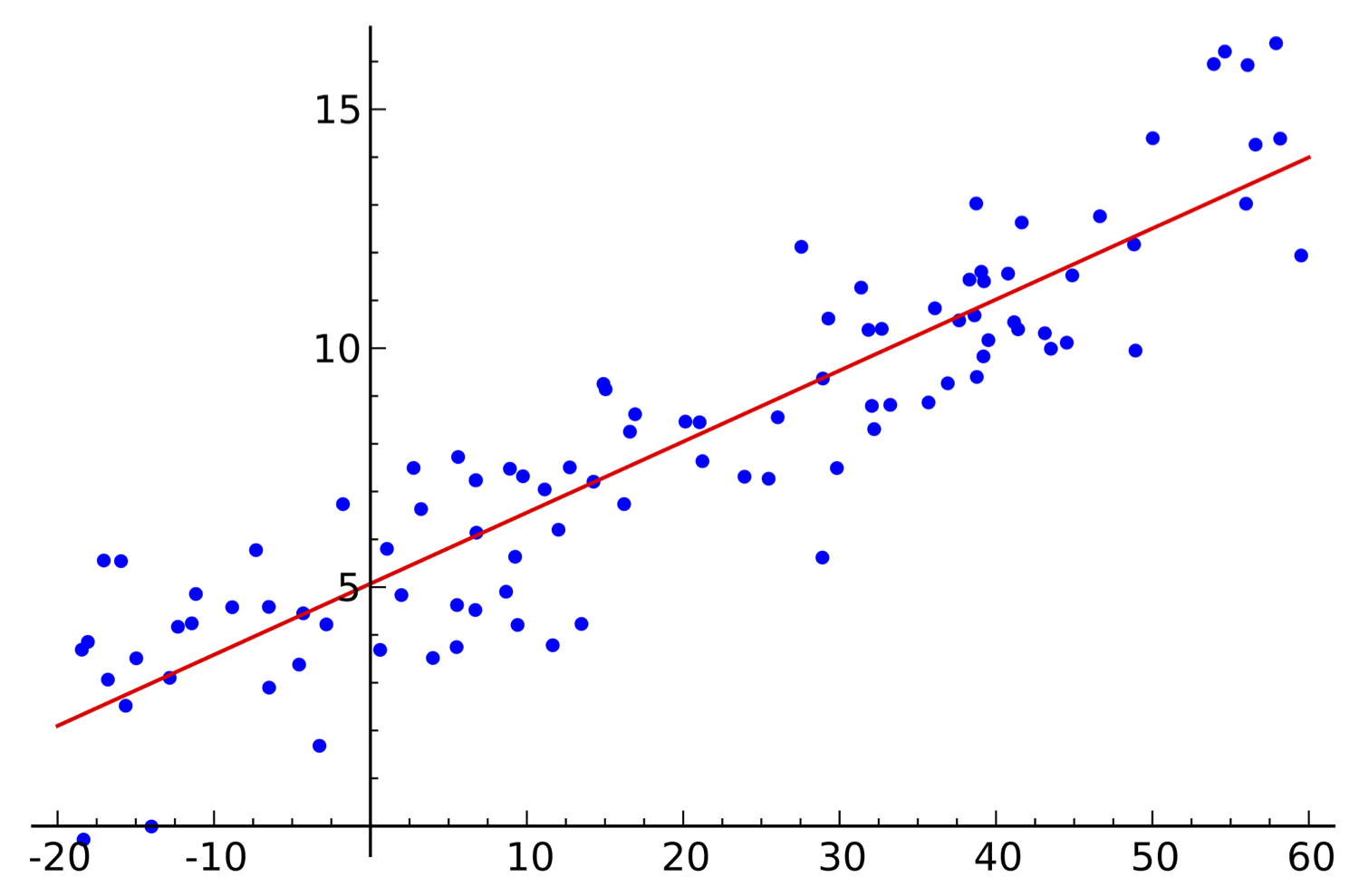
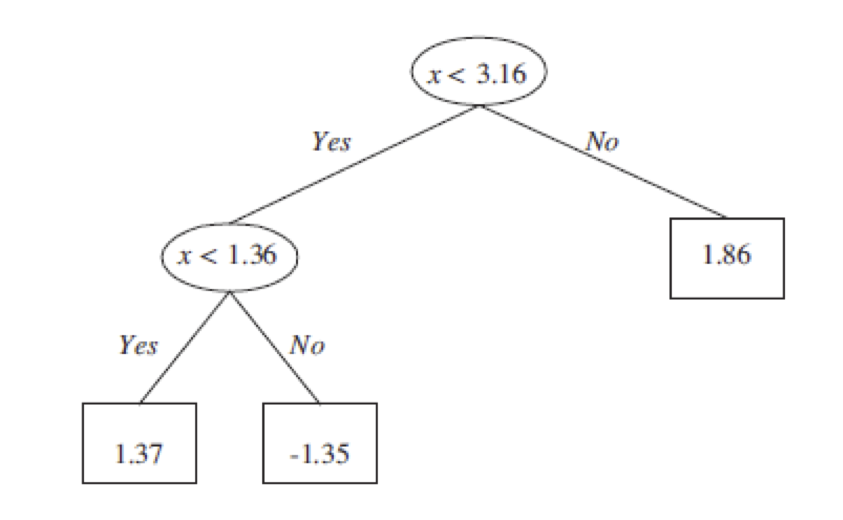
Regressziós döntési fák
A regressziós döntési fa modellje szintén egy döntési fa, ami a jellemzők közötti logikai kapcsolatot írja le. A osztályozt végző
döntési fához képest az eltérés a leveleken van. A regressziós döntési fa leveleiben vagy egy konstans érték vagy egy lineáris regressziós modell (minden levelén
különböző modell) van.
Regressziós kNN
A k legközelebbi szomszéd osztályozót is használhatjuk regresszióra. Itt is meg kell adnunk egy egyedek közti távolság/hasonlóság függvényt, ami alapján predikciós időben az ismeretlen egyedhez, a tanító adatbázisbeli k legközelebbi egyedet megkeresi az algoritmus. A tanító adatbázbeli szomszédokhoz most folytonos érték van rendelve (célváltozó). A regressziós kNN a k szomszéd tanító adatbázis célértékének átlagát - vagy hasonlósággal súlyozott átlagát - fogja predikálni.