Gépi tanulás alapfogalmai
A gépi tanulás (Machine Learning) különböző megközelítésekben valósítható meg. Ezek elsősorban abban térnek el egymástól, hogy hogyan tanítjuk a gépet, az milyen formában szerzi meg a tapasztalatot. Három főbb megközelítést szokás említeni:
- Felügyelt tanulás (supervised learning): a tapasztalatok itt egy megfigyelés/adat és a hozzá tartozó elvárt célérték.
A tapasztalatok halmaza egyben adott, ezt hívjuk tanító adatbázisnak (training dataset).
A cél, hogy ez alapján olyan modellt tanuljunk ami korábban nem látott példákon is helyesen működik.
Példa alkalmazás: ügyfélszolgálatra érkező e-mail panaszleveleket akarunk automatikusan továbbítani a megfelelő munkatárshoz, aki meg tudja válaszolni azt. Ehhez rendelkezésre áll több ezer e-mail a múltból (adat) és, hogy melyik munkatárshoz kellett irányítani a levelet (elvárt célérték). Ebből a tanító adatbázisból kell megtanulnunk egy modellt, ami a holnap érkező e-maileket a lehető legnagyobb pontossággal automatikusan a megfelelő munkatárshoz irányítja. - Felügyelet nélküli tanulás (unsupervised learning): A megfigyelésekhez nem áll rendelkezésre elvárt célérték (azaz felügyelet).
Célunk, hogy az adatok közt mintázatokat/összefüggéseket azonosítsunk. A tanítás itt a kérdéses mintázat/összefüggés definícióját jelenti,
ami általában számos mérnöki iteráció után alakul ki.
Példa alkalmazás: a vállalat ügyfeleiről rendelkezésre állnak azok múltbeli tranzakcióinak adatai. Találjunk olyan ügyfél csoportokat, akik hasonlóan viselkednek anélkül, hogy a viselkedési csoportokat előre megadnánk! Figyelem, mérnöki feladat, hogy két tranzakciósorozat hasonlóságt leírjuk! - Megerősítéses tanulás (reinforcement learning): a rendszer folyamatosan akciókat hajt végre, néha kap megerősítést, hogy
mennyire jól csinálja a feladatát, és ezekből a megerősítésekbő folyamatosan tanul.
Példa alkalmazás: Robotot tanítunk büntetőt rúgni fociban. A robot csak a büntetőrúgás végén kap visszajelzést, hogy sikeres volt-e. Ebből kell saját magának kialakítani a mozgássorozatot, amire majd megint kap megerősítést (aktív tanulás).

A kurzus túlnyomó részén a felügyelt gépi tanulással fogunk foglalkozni, egy óra erejéig bepillantást nyerünk a felügyelet nélküli gépi tanulásba, míg a megerősítéses tanulás nem témája a kurzusnak.
Alapfogalmak
Nézzünk egy újabb gyakorlati feladatot! Egy halkonzerv-gyárban dolgozunk, ahol a halak egy futószalagon érkeznek és jelenleg kézzel osztályozzák őket, azaz döntik el, hogy melyik csomagoló konzervbe kerüljön az adott hal. Az egyszerűség kedvéért tegyük fel, hogy csak két fajta hal érkezhet, lazac és sügér. A gyár felszerelt egy kamerát a futószalag fölé és célunk, hogy olyan gépi tanulási a megoldást dolgozzunk ki, ami a kameraképek alapján automatikusan eldönti, hogy lazac vagy sügér van a képen. A kamera felszerelése után, a tapasztalt kollégák 1000 halról készült kameraképről megmondják, hogy az lazac vagy sügér-e.

A feladat gépi tanulási, hiszen adott egy jól definiált feladat (halak besorolása a lehetésges két
osztály valamelyikébe) és elvárjuk, hogy több tapasztalat (kézzel felcímkézett kamerakép) esetén pontosabban legyen képes végrehajtani
a rendszer a feladatot.
A feladatot felügyelt tanulási megközelítésben oldjuk meg, hiszen előre adott a "tapasztalat" halmaz,
azaz az 1000 címkézett kép és a célunk, hogy eddig nem látott képekre is minél pontosabban működő rendszert építsünk.
Minden gépi tanulási feladatnál, legelőször meg kell határoznunk, hogy mik azok az egyedek/szituációk amikor döntést
akarunk hozni. Most egy kamerakép egy egyed.
A felügylet gépi tanuláson belül is megkülönböztetünk két feladattípust:
- Osztályozási feladat esetén adott kategóriák/osztályok egy halmaza, és a feladatunk, hogy az egyedeket az előre adott osztályok közül az egyikbe besoroljuk, a megfelelő osztálycímkével (class label) ellássuk/címkézzük.
- Regresszió esetén a célváltozó egy folytonos érték, a feladatunk, hogy ez egyedekhez megjósoljuk, hogy milyen érték tartozhat.
Ahhoz, hogy mérni tudjuk, hogy mennyire jól oldja meg a feladatot az osztályozó algoritmus, szükségünk van még egy kiértékelési metrikára is, ami számszerűsíti a rendszer teljesítményét. Ezzel a metrikával tudjuk ellenőrízni, hogy teljesül-e a 'több tapasztaltból jobb teljesítmény' gépi tanulási alapelv. A halosztályozós példában legyen a kiértékelési metrika a találati arány (accuracy), ami az az arány ahányszor helyes osztályba soroltunk egy egyedet. Figyelem, a kiértékelési metrika lesz majd a célfüggvényünk is! Egy osztályozási problémát több féle képpen is ki lehet értékelni (például ha a 'sügért rakunk lazacos dobozba' hiba sokkal súlyosabb, mint a 'lazacot rakunk sügéres dobozba' hiba), nagyon fontos, hogy a gyakorlati alkalmazási környezethez, a terület szakértőivel közösen, válasszuk meg a kiértékelési metrikát!
A tanító adatbázis alapján, a kiértékelési metrika, mint célfüggvényre optimalizálva, a gépi tanulás során felépítunk egy modellt. A modell a döntési szabály, ami tartalmazza az egyedek jellemzői közti feltárt kapcsolatokat/mintázatokat/szabályszerűségeket. A modell képes korábban nem látott egyedekre is döntést hozni.

Jellemző leírás
A gépi tanuló megoldások nem képesek a nyers adatokból közvetlenül tanulni, szükség van az egyedek numerikus leírására, jellemzésére.
Ehhez a gépi tanulási mérnöknek definiálnia kell azokat a jellemzőket/attribútumokat (feature), amelyek strukturált formában
tartalmaznak információt az egyedekről a gépi tanuló rendszernek. A gépi tanulás során a modell ezen jellemzők közti összefüggéseket/szabályszerűségeket
fogja megtanulni. Kinyerhetünk bármilyen jellemzőt, ami segíthet a modell felépítésében, a gépi tanulástól elvárjuk, hogy azt is
megtanulja, hogy például egy jellemző "felesleges", azaz nincs hozzáadott értéke az adott gépi tanulást döntés meghozatalához.
A halas példánkban az egyedeket (halak) leírhatjuk például hossz (cm), pikkelyfényesség (lumen) vagy napszak (de/du) - tfh nagyobb
valószínűséggel érkezik sügér a gyárba reggelente - jellemzőkkel.
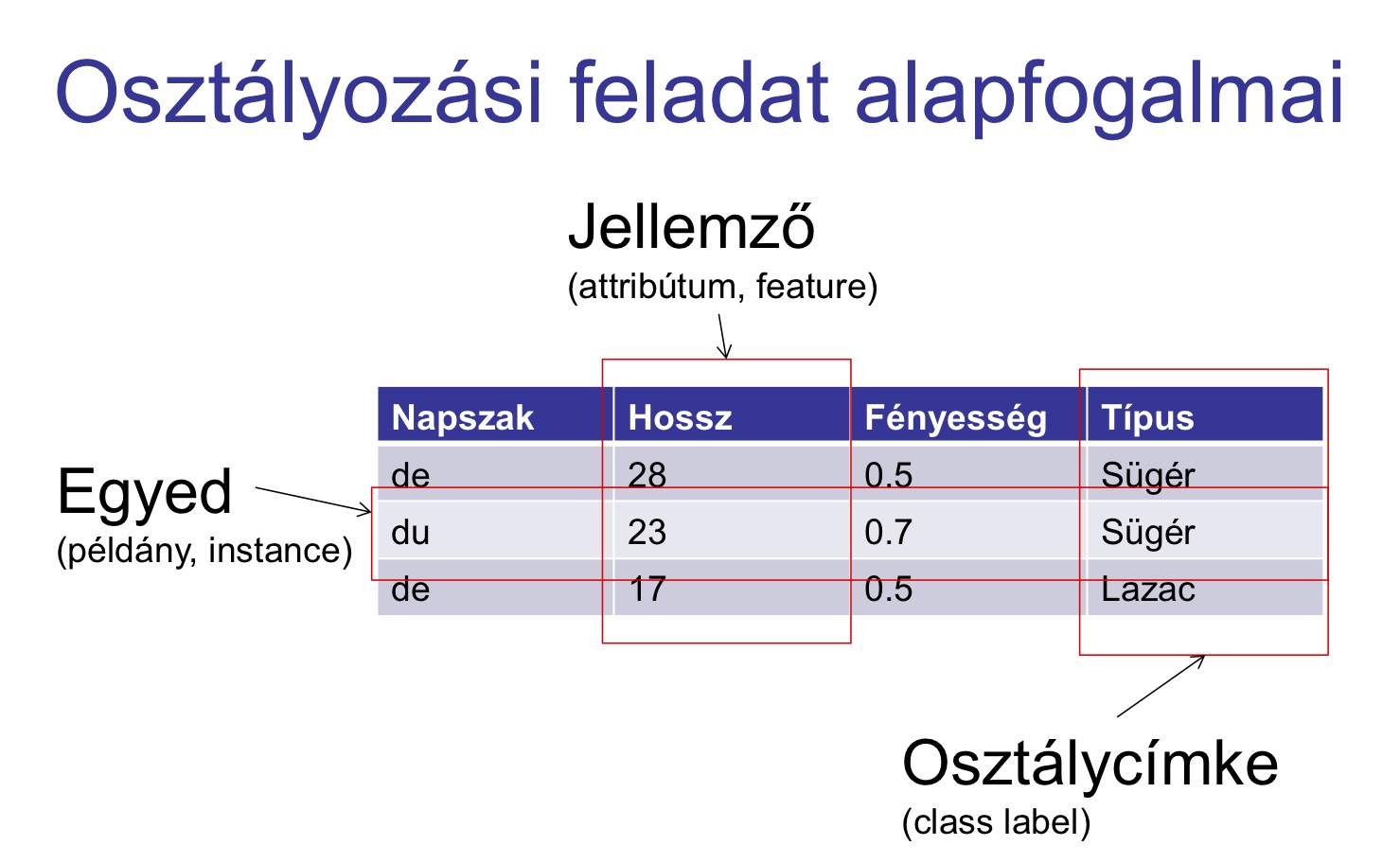
Jellemző kinyerés
A gépi tanulási mérnök feladata, hogy a feladathoz szükséges jellemzőkészletet definiálja (feature engineering) és
implementálja a jellemző kinyerő (feature extraction) kódokat, amelyek a nyers adatból kiszámolják minden egyedre
az egyes jellemzők értékeit. Az egyes konkrét egyedeket leíró jellemző-érték párokat az egyed jellemző vektorának (feature
vector) hívjuk.
Megjegyezzük, hogy a jellemző kinyerés bemenete csak az egyed nyers adata, nem használhatja fel a célváltozó (pl. osztálycímke)
értékét a tanító adatbázisból, hiszen a predikció során először az ismeretlen nyers adatból jellemzőket kell kinyernünk, majd a
jellemzővektoron tudjuk alkalmazni a tanult modell döntési szabályait.
Jellemzők fajtái
Az egyedeket leíró jellemzők sokfélék lehetnek, egy folyton értétől egy időpontig bármi. A legtöbb gépi tanulási szoftverkörnyezet két alaptípust kezel:
- Folytonos/numerikus jellemző: lebegőpontos racionális szám, értékkészlete \(-\infty...\infty\) (pl. ember magassága)
- Diszkrét/kategórikus jellemző: a lehetséges értékek egy halmazt alkotnak, köztük nincsen semmilyen reláció (pl. ember hajszíne)
A döntés a gépi tanulási mérnök kezében van. Ha diszkrét változónak kezeljük ezt a jellemzőt, akkor külön szabályokat fog tanulni a modell mind az öt értékre. Ha numerikusként kezeljük, akkor valószínűleg egyetlen szabályban fog szerepelni ez a jellemző, például 'ha jegy>3 akkor'. Fontos különbség, hogy diszkrét változóként a gép nem feltételez semmilyen kapcsolatot az értékek között (még sorrendiség sincsen), az {1,2,3,4,5} csak azonosítók lesznek, nyugodtan írhatunk {kék,piros,sárga...} helyette.
A Gépi tanulási mérnök feladatai
Egy gépi tanulási feladat során a mérnöknek több különböző ponton kell biztosítani a rendszer optimális tanítását. Ez agilisan kell, hogy működjön. Minél hamarabb kell egy első működő rendszer, meg kell érteni, hogy a rendszer gyenge pontjai hol vannak és azokon kell javítani iterációs ciklusokban!

- Az adatgyűjtés során a szükséges nyers adatokat kell elérhetővé tenni, összerkötni, tisztítatni. Mérnöki kérdés, hogy honnan tudjuk, hogy elegendően nagy és reprezentatív mintát (példát, samples) gyűjtöttünk a rendszer tanításához és teszteléséhez?
- Gyakran van szükség a bejövő adatok, problémétól független előfeldolgozására. Például ha képekkel dolgozunk, akkor azok méret- és szín normalizálására vagy nem lényegi részek levágására. Az előfeldolgozás szabályalapú rendszerekkel történik. A jó teljesítmény elérésében sokkal fontosabb szerepet játszik, mint ahogyan azt sokan feltételezik!
- A jellemző kinyerés során újabb és újabb jellemzőket implementálunk, ezzel tudunk újabb információt bevinni az egyes egyedekről a rendszerbe.
- Számtalan gépi tanulási módszer érhető el. Minden feladathoz más módszer működik jól. NO FREE LUNCH! Ez függ a jellemzők számától és típusától, tanító adatbázis méretétől, de lehetnek más funkcionális követelmények (pl. futásidő, memóriahasználat) ill. nem-funkcionális követelmények (pl. modell emberi értelmezhetősége) amelyek a megfelelő módszer választását befolyásolják.
- A kiválasztott módszer tanításánál a módszer paramétereinek finomhangolása a mérnök feladata.
- Az aktuális modell/megoldás számszerű kiértékelése megmutatja a rendszerünk teljesítményét. Egyes hibák elemzésével, vagy hibák statisztikának értelmezésével meg kell értenünk, hogy miért hibázik a rendszer, hiszen csak így tudunk javítani azon.
Egy iteráció végén, sok lehetőségünk van a gépi tanuló rendszer teljesítményének javításán. Lehet, hogy több vagy más típusú adatra (ami közelebb áll az éles adathoz) van szükség, vagy újabb jellemzőket nyerünk ki, vagy más gépi tanuló módszerrel kísérletezünk. Legyünk agilisek, inkrementálisan javítsuk a rendszer teljesítményét!