Gépi tanulás a szövegbányászatban
Szövegbányászat (Natural Language Processing, NLP)
Óriási mennyiségű adat érhető el strukúrálatlan, például szöveges formában. Ezen adatok automatikus feldolgozását nevezzük szövegbányászatnak (Text Mining) vagy nyelvtechnológiának (Natural Language Processing, NLP) vagy
számítógépes nyelvészetnek (Computational Linguistics). Az emberi nyelvek gyönyörűek. Ugyanazt száz féle képpen ki tudjuk fejezni és egy szó vagy kifejezés sok mindent tud jelenteni más mondatkörnyezetben.
A nyelvtechnológia tehát a mesterséges intelligencia egyik területe, az emberi nyelv írott szöveg számítógépes megértésével, ember és számítógép közti szöveges kommunikációval foglalkozik. Az emberek által,
emberi olvasásra írt szövegek gépi értelmezése máig megoldatlan probléma. Azonban a szövegek feldolgozásában és generálásában rengeteget fejlődött a technológia az elmúlt 20 évben.
Nyelvtechnológiai alkalmazások
Számtalan célalkalmazás van, ahol emberek által írt szövegeket kell számítógéppel megértenünk és/vagy ember számára érthető szöveget kell algoritmikusan generálnunk. A teljesség igénye nélkül, néhány ilyen célalkalmazás:
- Chatbot, intelligens asszisztens: a felhasználó szöveges (gépelt vagy beszédből szövegátirat) kérését fel kell dolgozni, megérteni, hogy mire
vonatkozik a kérés, majd emberi nyelven megfogalmazni a választ.
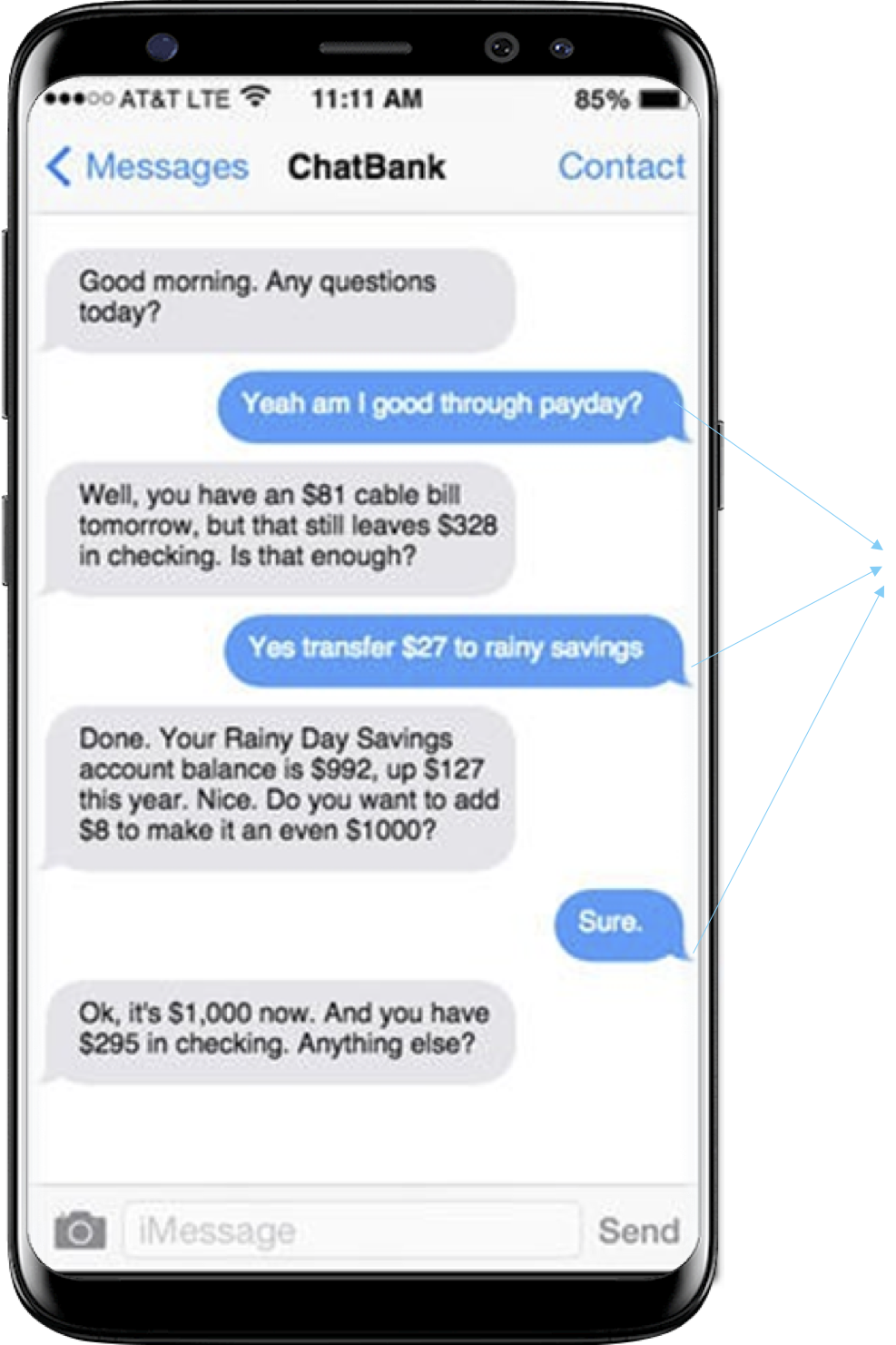
Egy elképzelt példa beszélgetés az intelligens banki asszisztenssel. - Gépi fordítás (machine translation): egyik egész szöveget kell egy forrásnyelvről (pl. koreai) lefordítanunk a célnyelvre (pl. magyar) úgy, hogy a fordítás a lehető legjobban visszaadja a forrásszöveg tartalmát. A személyes felhasználás területén piacvezető a Google Translate.
- Dokumentumokat osztályozhatunk számos szempont szerint. Osztályozási szempont lehet a dokumentum fő témája, vagy akár a szerző által kifejezett érzelmek/vélemények is.
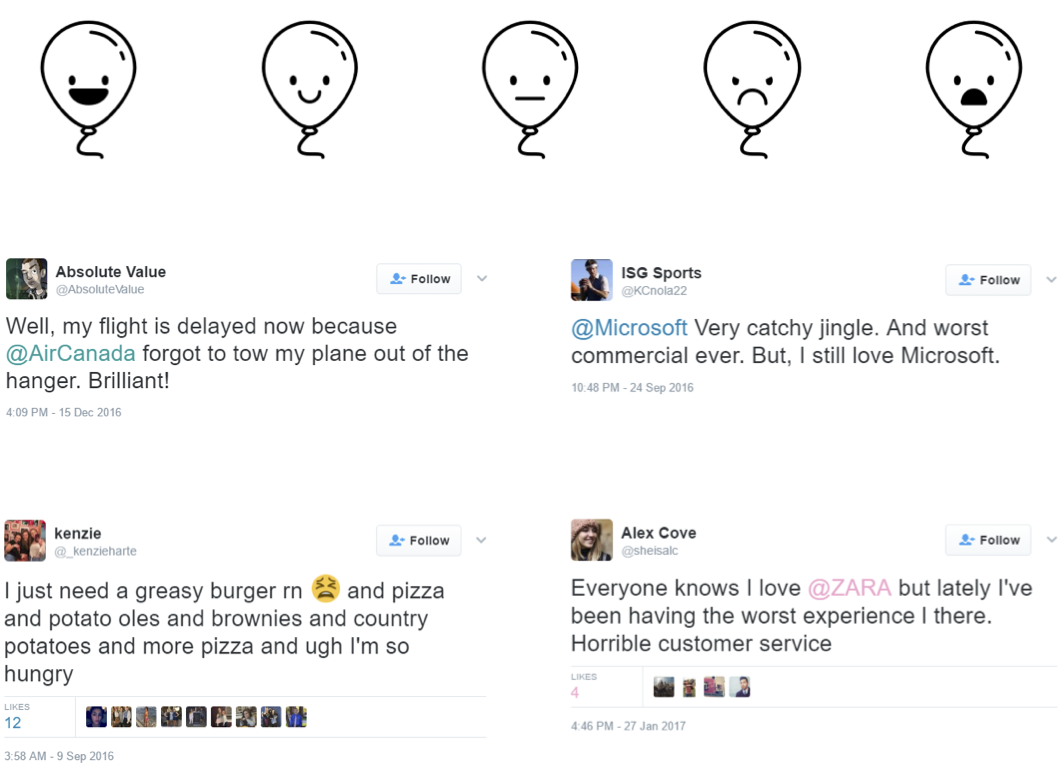
Nézd meg a megjegyzésekkel ellátott PPTt a Black Swan Szegeden folyó szövegbányászati munkájáról. - Az információ kinyerés (information extraction) célja, hogy a dokumentumokat mélyebben elemezze. Segítségével pl. üzleti hírek szövegeiből kinyerhetünk olyan strukturált adatbázist
ami tartalmazza, hogy melyik cég, melyik másik cég, hány százalékos tulajdonrészét vásárolta meg, mikor és mennyiért. Például:
A NagyHal ZRt. tegnap előtt bejelentette, hogy a jövő keddi hatállyal birtokába kerül a KisHal Kft. 55%-os tulajdonrésze.
Vagy biológiai tudományos publikációk elemzésével építehetünk adatbázist, hogy milyen fehérjék közt mutattik ki kapcsolatot kutatók korábban. Az információ kinyerés struktúrálatan (nyers folyószöveg) adatból struktúrált adatot (adatbázisrekordok mezőkkel) állít elő.
Szöveges tartalmak előfeldolgozása
A nyelvtechnológai alkalmazások tipikusan két fázisból épülnek fel. Az első lépésben a nyers folyószövegek előfeldolgozáson esnek át. Ez tipikusan nem függ (vagy csak kis mértékben) a célfeladattól, viszont minden nyelvre más megoldásra van szükség.
A szöveg feldolgozása a gépi tanulás előtt elengedhetetlen, hiszen a szöveg strukturáltalan adat, a gépi tanuló algoritmusok pedig jellemzővektorok kezelésére képesek.
A leggyakrabban alkalmazott előfeldolgozási lépések:
- Mivel a legtöbb nyelvben a szöveg alapvető alkotóelemei a szavak, így általában a szöveges adat feldolgozása során elsőként a dokumentumokat szavak sorozatára bontjuk fel (tokenizálás).
- Legtöbbször az egyes szavak többszöri, csupán kis- és nagybetűs írásmódjukban eltérő szavakat azonosnak szeretnénk tekinteni (pl.: Magyar, magyar, MAGYAR), ekkor a szöveg karaktereit kisbetűssé alakítjuk, hogy a különböző alakok elveszítsék különbözőségüket.
- Időnként a szavak különbözőképpen ragozott írásmódjait sem szeretnénk megkülönböztetni, ekkor valamilyen szótövesítő eljárást alkalmazunk, ennek folyamata erősen függ a feldolgozni kívánt nyelvtől. Azokon a nyelveken, melyeken ehhez rendelkezésünkre áll megfelelő minőségű lemmatizáló szoftver, minden toldalékolt szót helyettesíthetünk a szótári alakjával. Sokszor azonban csak levágjuk az utolsó karaktereket (stemming), ekkor a kapott alak nem feltétlenül a szó nyelvtanilag helyes töve lesz.
- Legtöbbször a szövegből eltávolítjuk az írásjelek egy meghatározott halmazát, amik a szavak szintjén nem bírnak jelentéssel.
- Szintén bevett eljárás az adott nyelvre jellemző gyakori és önmagukban jelentést nem hordozó szavak eltávolítása, ebbe a kategóriába tartoznak a névmások, névelők, kötőszavak stb. Ezt az eljárást stopszó szűrésnek nevezzük.
- Gyakran szükségünk van még a szavak szófajának meghatározására (POS tagging) is. Például ha ki akarjuk szűrni a mellékneveket.
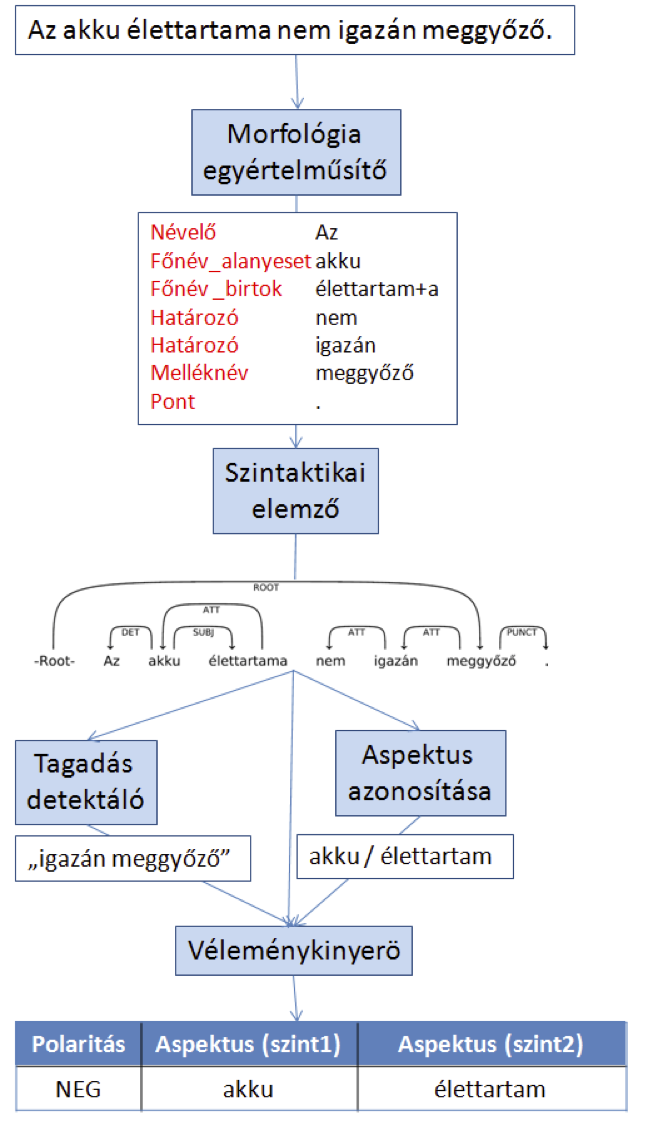
Jellemzőkinyerés szövegekből
A dokumentum osztályozási feladatnál az egyedek a dokumentumok (folyó szöveges) és egy előre adott osztályhalmazba kel azokat besorolnunk. Ahhoz, hogy az osztályozót gépi tanulhassuk, az egyedeket
jellemzőkkel kell leírnunk. Ehhez először, a fenti előfeldolgozási lépéseket végre kell hajtanunk, aminek kimenete a szavak tisztított és kiegészítő információval ellátott listája.
Dokumentumok jellemzőkkel leírására a bevett módszer az ún. szózsák (bag-of-words) modell, melynek során egy szótárt alkotunk, melybe belekerül a dokumentumhalmazunk összes szava. Ez a szótár lesz az adatbázisunk jellemzőkészlete.
Ezt követően pedig az egyes dokumentumokra leszámoljuk, hogy abban a szótár egyes szavai hányszor szerepelnek (term frequency), ez adja meg az egyed jellemzővektorát. Így minden dokumentumhoz rendelt jellemzővektor hossza azonos lesz
megegyező a szótár hosszával (egy szótárelem nem szerepel a dokumentumban 0 a jellemző értéke), ami azért fontos, hiszen a modellezés során azonos hosszú jellemzővektorokat szeretnénk kezelni.

Végül ha azt szeretnénk, hogy az egyes jellemzők/szavak súlya ne pusztán az előfordulásuk számát reprezentálja az adott dokumentumban, hanem az adott szó prediktív erejét is, akkor az ún. Tf-idf (term frequency inverse document frequency)
súlyozást szoktuk jellemzőértéknek használni. Itt ún. idf (inverse document frequency) érték azon dokumentumok számának inverze, amelyben az adott szó megtalálható az adatbázisunkban. Ha egy szó majdnem minden dokumentumban előfordul, akkor
nem sokat segít majd a dokumentumokat osztályozó modell megalkotásában, ezért kisebb súlyt érdemes hozzárendelni.
\[ tfifd(w,d) = tf(w,d) log(\frac{1}{df(w,D}) \]
Egy szó Tf-idf értéke arányosan nő a szó előfordulási gyakoriságával a dokumentumon belül, illetve csökken, minél gyakoribb az adott szó a teljes adatbázisban.