
Features used for identifying the texture
In order to classify the textures some charactersitics should be be taken. These charactersitcs we call features and are grouped into the feature vector. Each feature is represented as a number, forming a vector which on some charactersitic way identifies the texture in a feature vector space.
We use following set of textures
- Statistical (taken from co-occurence matrix and include entropy, contrast, correlation)
- Frequency (energy of different bands are taken)
- High level (taken from watershed algorithm)
From the co-occurrence matrix we take out statistical features. High level algorithm is a watershed algorithm where number of filled holes is counted. In frequency domain, frequency spectrum is divided into three circular bands (which gives invariance to rotation + invariance in translation) and energy is calculated. Before doing the FFT image is normalized.
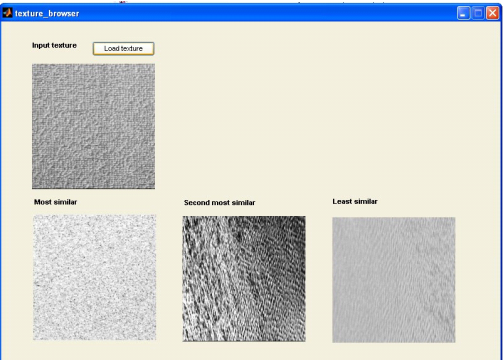
Working application
When building the database one encounters following problems: What is the best way to represent the textures How to compare that two vector are similar How to make computing fast Our first approach was in bulding the SVM classifier where each texture's feature vector would be represented as one class, and on input which is a feature vector of a texture we are searching similar for, SVM would give us nearest class (texture). Problem with this approach is in small set of training vector, retraining of a classifier for each new vector in the database and problem with constructing the classifier for such large set of the classes. Our approach consists of measuring the distance between feature vector and selecting the closest one.