Lokális osztályozók
Ha az osztályozási feladat olyan, hogy kézenfekvő módon tudunk az egyedek közt hasonlósági (vagy távolság) függvényt megadni, akkor a legegyszerűbb osztályozási megközelítést érdemes alkalmaznunk, az ún. k legközelebbi szomszéd (k nearest neighbour, kNN) osztályozót. Tehát tegyük fel, hogy adott egy osztályozási feladat és egy címkézett tanító adatbázis valamint egy függvény, ami számszerűsíti bármely két egyed távolságát. Ekkor, a k legközelebbi szomszéd osztályozó algoritmus úgy predikál, hogy
- megkeresi a tanító adatbázisban azt a k darab egyedet amelyek a leghasonlóbbak a predikálandó egyedhez (a hasonlósági függvény maximuma/távolság függvény minimuma a kérdéses egyed és a tanító példa közt). Ezek lesznek a legközelebbi szomszédok.
- Majd a k legközelbbi szomszéd osztálycímkéiből kiválasztja a leggyakoribbat és azt predikálja.

A kNN a lineáris gépekhez hasonlóan folytonos jellemzőterek esetén használatos. Míg azonban a lineáris gépek egy olyan osztályokat elválasztó döntési felület keresnek ami globálisan, az egész jellemzőteret átszeli, a kNN a jellemzőtérben lokális információk alapján dönt, hiszen a szomszédságon/lokális környezetn kíül eső tanító adatbázisbeli egyedek egyáltalán nem játszanak szerepet az osztályozási döntésben.
A k legközelebbi szomszéd osztályozó egy érdekessége, hogy nincs modellje. Minden egyes predikciónál ki kell számolni a páronkénti távolságot a kérdéses egyed és az összes tanító adatbázisbeli elem között, hogy a legközelebbi szomszédokat megtaláljuk. Nincs modell, de a gépi tanulás szükséges feltételét, miszerint egyre nagyobb tanító adatbázisból egyre jobb osztályozási pontosságot érjünk el, teljesíti.
kNN a gyakorlatban
A k legközelebbi szomszéd osztályozó teljesítménye azon áll vagy bukik, hogy milyen távolság/hasonlóság függvényt definiálunk. A gyakorlatban sajnos
ezzel nem nagyon törődnek a mérnökök. Ha az egyedek le vannak úgyis írva egy jellemzőkészlettel akkor egyszerűen a két jellemzővektor valamilyen
standard vektortávolságát (koszinusz vagy euklideszi távolság) szokták használni. Ez nagyon veszélyes!
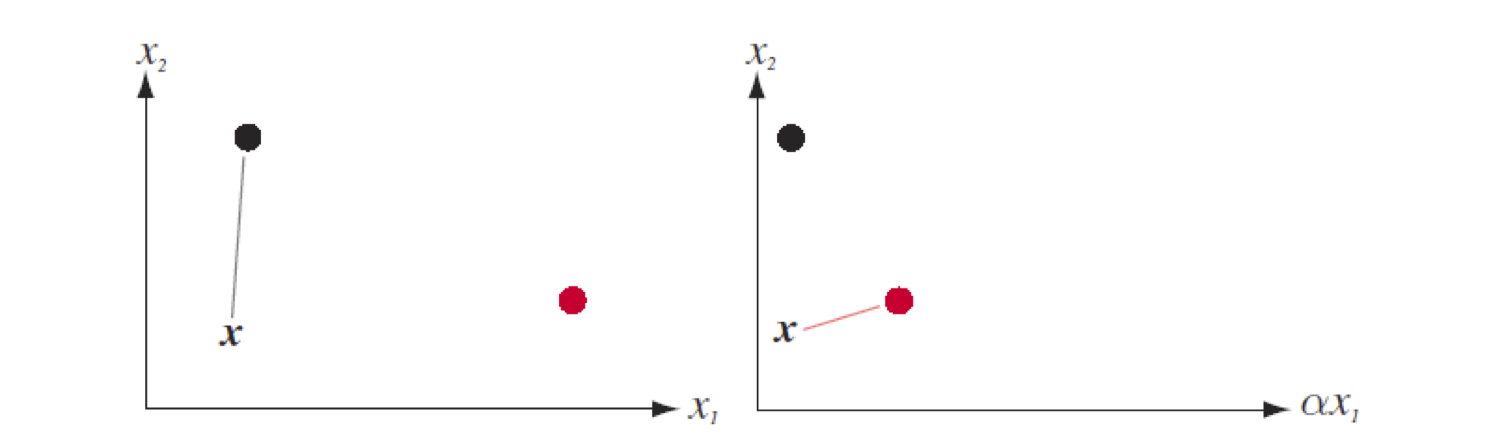
Legyen megint két jellemzőnk \(x_1\) és \(x_2\), valamint két osztályunk piros és fekete. Továbbra is használjuk a 2 dimenziós euklideszi távolságot.
A tanító adatbázisunk csak egy-egy példából áll az alábbi ábrákon. A bal oldali ábrán a predikálandó x ponthoz a fekete tanító példa van közelebb, így
a k=1 legközelebbi szomszéd osztályozó feketét predikál. Szorozzuk meg minden egyed \(x_1\) értékét egy \(\alpha\) konstanssal (például eddig cm-ben volt
megadva egy méret, amit innentől dm-ben szeretnénk tárolni \(\alpha\)=0.1). Ekkor már a piros tanító példa lesz közelebb a kérdéses x egyedhez és azt fogja
a k=1 legközelebbi szomszéd osztályozó feketét predikálni! Pedig az egyedeink nem változtak semmit...
kNN előnyei:
kNN hátrányai:
- Jó távolság függvény mérnöki megadása nagyon nehéz.
- Ha a tanító adatbázis nagyon nagy, lassú lehet a predikció. (Ennek orvoslására számtalan térindexelésen alapuló megoldás létezik, lásd k-d tree.)