Osztályozás gépi tanulással
A leggyakoribb gépi tanulási feladat az osztályozás (classification). Itt előre adott egy kategória-/osztályhalmaz és a célunk,
hogy felügylet gépi tanulási megközelítésben olyan modellt/döntési szabályokat tanuljunk a tanító adatbázis alapján, ami képes
egy ismeretlen példát minél pontosabban valamelyik osztályba (class) sorolni (úgy is mondjuk, hogy 'címkézni' (labeling)).
Osztályozási feladat például a jól ismert macska vs. kutya feladat, ahol képeket kell a {macska, kutya} két osztály valamelyikébe besorolni.


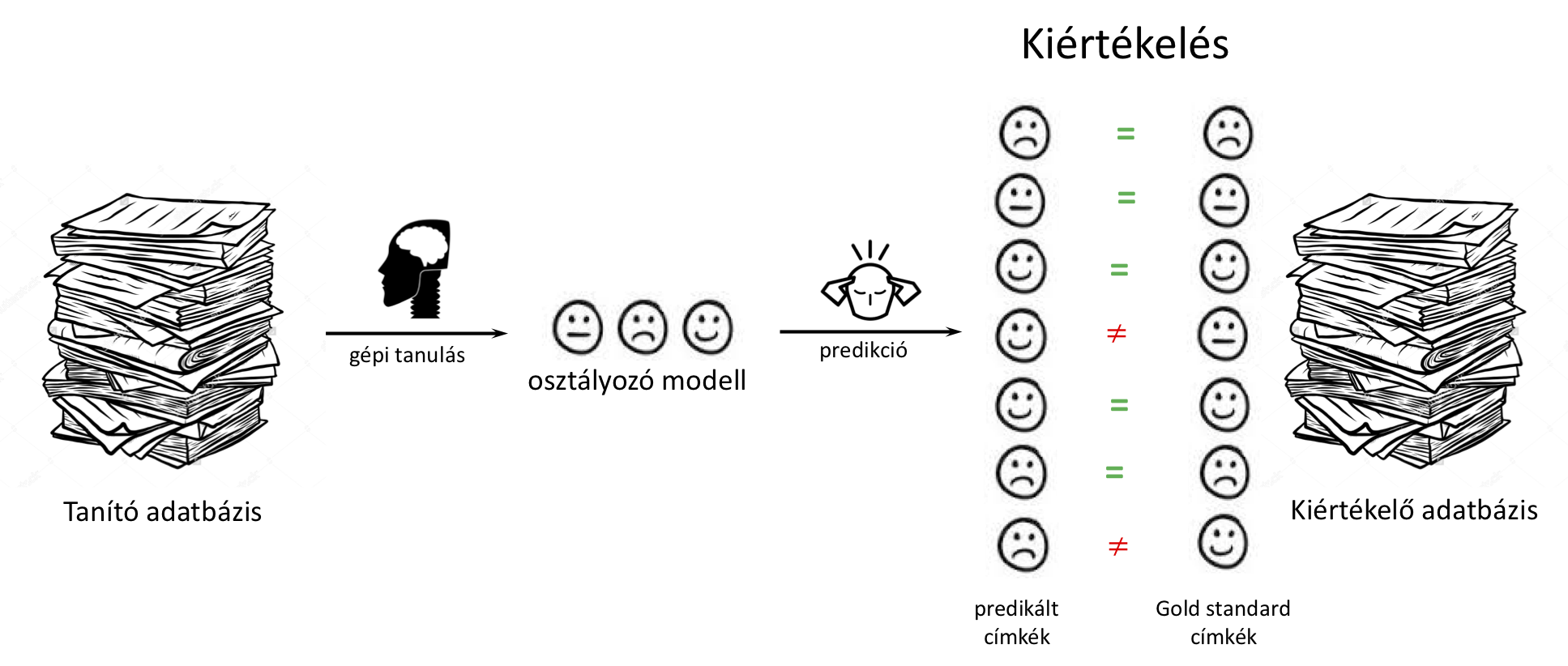
Felügyelt gépi tanulási módszerek kiértékelési módszertana
Tegyük fel, hogy osztályozási problémára, tanító adatbázis alapján, építettünk egy modellt (legyen az akár egy egyszerű baseline megoldás
vagy egy szofisztikált gépi tanult megoldás). Hogyan tudjuk a modell teljesítményét/pontosságát számszerűen/objektíven megmérni, azaz kiértékelni ezt a modellt?
Első gondoltunk lehet az, hogy a tanító adatbázis minden egyedére megnézzük, hogy a modell predikciója megegyezzik-e a helyes (gold-standard) osztálycímkével és mondjuk
a helyes válaszok aránya lesz a kiértékelési metrika. Jó ez a módszertan!?
Nem helyes ez a módszertan! Emlékezzünk vissza a felügyelt gépi tanulás definíciójára! A célunk, hogy a tanító adatbázis
alapján olyan modellt tanuljunk, ami utána korábban nem látott egyedeken is pontos döntést hoz (pl. osztályba sorol). A tanító adatbázison kiértékeléssel
nem azt mérjük, hogy korábban nem látott egyedeken hogyan teljesít a modell! Az a modell ami "bemagoljuk" a tanító adatbázist, az esetek többségében helyes
predikciót csinál a tanító példákon, DE ha nincs általánosítási készsége, akkor a tanító adatbázison kívüli elemeken nagyon pontatlan lesz.
Annak érdekében, hogy a modell pontosságát korábban nem látott/ismeretlen egyedeken tudjuk kiértékelni a rendelkezésre álló címkézett adatbázist véletlenszerűen
két részre, ún. tanító- és kiértékelő adatbázisok (train ill. evaluation/test set) ra bontjuk. A tanulás során csak a tanító adatbázist láthatja/használatjuk, ezzel szimuláljuk,
hogy a kiértékelő adatbázis egyedei ismeretlenek/korábban nem látottak (leave-out vagy hold-out dataset), hiszen azokat nem használtuk a tanítás során.
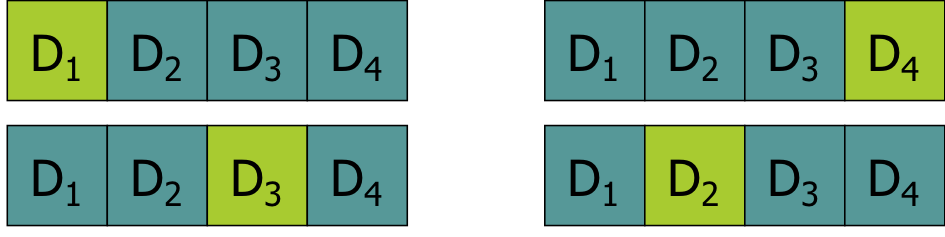
A legismertebb többször megismételt tanító/kiértékelő halmaz vágási módszertan az ún. \(k\)-szoros keresztvalidáció (\(k\)-fold cross validation). Itt a rendelkezésre álló
címkézett adatbázist \(k\) egyenlő méretű részre bontjuk majd \(k\) darab kísérletet futtatunk le. Minden kísérletben az egyik részhalmazt használjuk kiértékelő adatbázisnak és
a többi \(k-1\) részhalmaz egyedeit használjuk tanító adatbázisnak.
Osztályozási feladat kiértékelési metrikái
Tegyük fel, hogy egy osztályozási feladat kiértékelő adatbázisának minden \(n\) db egyedére adott a helyes/elvárt osztálycímke és egy modell által az egyedre predikált osztálycímke. A legegyszerűbb metrika a találati arány (accuracy) - röviden \(acc\) -, amivel osztályozó modellek teljesítményét jellemezhetjük: \[ acc = \frac{helyes}{n} \]
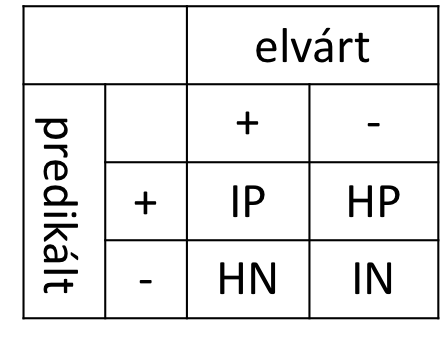
Ha jobban meg szeretnénk érteni az egyes osztályokon elért teljesítményt akkor érdemes különböző eseteket megkülönböztetni. tegyük fel, hogy két osztályunk van {pozitív +, negatív -}. Legyen
- Igaz pozitív (IP, true positive), amely a modell által helyesen prediktált pozitív esetek számának felel meg.
- Hamis negatív (HN, false negative), amely azon pozitív esetek számának felel meg, amelyeket a modell tévesen negatívként predikál.
- Hamis pozitív (HP, false positive), amely azon negatív esetek számának felel meg, amelyeket a modell tévesen pozitívként predikál.
- Igaz negatív (IN, true negative), amely az osztályozási modell által helyesen prediktált negatív esetek számának felel meg.
Egy konkrét P osztályon elért teljesítményt mérhetjük:
- pontosság (precision): P osztály pontossága azt fejezi ki, hogy amikor a rendszer P osztálycímkét predikált, akkor hány százalékban volt igaza. \[ pontosság(P) = \frac{IP}{IP+HP} \]
- fedés (recall): P osztály fedése azt fejezi ki, hogy az adatbázisban szereplő elvárt P-ek közül hányat talált meg/fedett le a rendszer. \[ fedés(P) = \frac{IP}{IP+HN} \]
- Az \(F_1\)-mérték a pontosság és fedés harmónikus közepe. Segít ha egyetlen számmal szeretnénk egy osztályon elért teljesítményt leírni. \[ F_1(P) = \frac{2 * pontosság(P) * fedés(P)}{pontosság(P) + fedés(P)} \]
Ha több, mint két osztályunk van, akkor is minden osztályra külön-külön számolhatjuk a pontosság és fedés értékeket, ebben az esetben az összes többi osztály uniója lesz a negatív osztálycímke.
A megfelelő kiértékelési metrika kulcsfontosságú egy gépi tanulási alkalmazás fejlesztésénél! Gondoljunk csak bele, ha olyan képosztályozót fejlesztünk, ami röntgen képek alapján próbálja megmondani, hogy adott betegségben szenved-e a páciens (bináris osztályozási feladat), akkor nem mindegy az elvárt rendszer a betegség osztály pontosságát (akire betegséget predikálunk az tényleg legyen az) vagy fedését (ne veszítsünk el beteg eseteket, nem baj ha tévesen betegnek predikáltak száma nagyobb) tekinti fontosabb szempontnak.