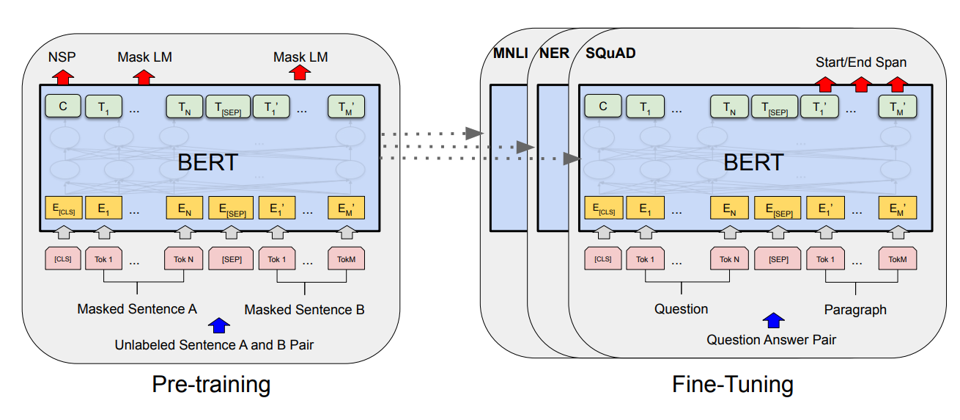
Finomhangolás (fine-tuning)
Az eddig tárgyalt gépi tanulási megközelítésekben élesen elkülönítettük a jellemzőkinyerési és modellépítési (tanulás) feladatokat. A reprezentáció tanulás kiváltja a mérnökök magasabb szintű jellemzőket kinyerő implementációs feladatait, tekinthetünk rá úgy, mintha a jellemzőket is gépi tanulnánk. Pontosabban nagyon alacsony szintű jellemzőkből (mint képek pixeljei) gépi tanuljuk a magasabb szintű jellemzőket, ezek lesznek a rejtett beágyazások. Ha a reprezentáció tanulásra mint jellemzőkinyerésre tekintünk, és mind a jellemzőkinyerés tanulása, mind a feladat-specifikus modellépítés neurális hálózatok segítségével történik, akkor egyetlen neurális hálózatot is használhatunk a két feladatra, azaz nem kell élesen elválasztani a kettőt.
A szövegfeldolgozás és képfeldolgozás során órási jelöletlen adathalmazokon előtanított (pre-trained) beágyazások állnak rendelkezésre. Ezek a nagy nyelvi modellek (Large Language Models, LLMs) esetében és képeknél mindig dinamikusak, azaz egy neurális hálózat kódolja (encode) a bemeneti szöveget vagy képet. A kódolás eredményét, egy beágyazás vektort használhatunk az egyed jellemzővektoraként és elkülönített lépésben erre építhetünk modellt. De magát a kódoló neurális hálózatot is elérjük és építhetünk egy olyan neurális hálózatot, amiben a kódoló neurális hálózat fölé helyezünk alkalmazás-specifikus rétegeket. Ebben az új hálózatban az alsó rétegekben az előtanított súlyokat használják, míg az új rétegeket véletlenszerűen inicializáljuk, majd felügylet gépi tanulási módon tanítjuk az egész hálózatot egy feladat-specifikus tanító adatbázis segítségével.
Vegyük észre, hogy ebben a tanítási folyamatban az előtanított hálórész súlyait is frissítjük. Ennek eredménye az lesz, hogy az eredeti előtanított kódoló hálórész - ami csak általános reprezentációra lett tanítva - is finomhangolódik a konkrét célfeladatra. Ezt a megközelítést finomhangolásnak (fine-tuning) hívjuk. A finomhangolás eredményeként a kódoló hálórész a felügylet tanulási feladat számára hasznosabb, a tanító adatok témájához/stílusához/karakterisztikájához jobban illeszkedő reprezentációt ad, mint az eredeti általános kódoló. Ezt az finomhangolt kódoló hálórészt újra kivághatjuk és más feladatokban tovább finomhangolhatjuk. Általában egy feladatra finomhangolt kódoló rosszabbul teljesít más típusú adatokon, mint az általános kódolók.