Apache Hadoop és HDFS
Összefoglalás
A lecke fejezetei:
- 1. fejezet: Hadoop klaszter létrehozása és futtatása Docker segítségével (olvasó)
- 2. fejezet: HDFS használata, alapvető parancsok (videó)
Olvasási idő: 30 perc
 1. fejezet
1. fejezet
Apache Hadoop klaszter indítása
Ahogy azt az előadásban is láthattuk, az Apache Hadoop keretrendszer és a HDFS elosztott fájlrendszer üzemeltetéséhez több szoftverkomponensre is szükségünk van: NameNode, ResourceManager, DataNode, HistoryNode, stb. Ebben a fejezetben bemutatjuk, hogy lehet telepítés nélkül, viszonylag egyszerű módon egy ilyen klasztert tetszőleges gépen beüzemelni. Ehhez a Docker [1] konténer szoftvert és előre elkészített konténer fájlokat fogunk használni. A Docker rendszer bemutatása nem tartozik jelen anyag keretébe, de az alábbi forrásokból további információk szerezhetők róla:
- https://www.youtube.com/watch?v=fqMOX6JJhGo
- https://www.youtube.com/watch?v=zJ6WbK9zFpI
- https://docs.docker.com/get-started/
Docker elérhető az összes fontosabb operációs rendszerre, a következők feltételezik, hogy rendelkezésre áll egy telepített Docker rendszer a gépen, ami a hivatalos dokumentáció [1] alapján könnyen kivitelezhető. A klaszterhez szükséges egyes node-ok képfáljai GitHub-on elérhetők [2], a példa során innen fogjuk letölteni őket.
Képfájlok letöltése és Hadoop klaszter indítása
Első lépésként a Big Data Europe GitHub repozitóriumból töltsük le a megfelelő képfájlokat. Ehhez feltétel, hogy a Git [3] verziókövető elérhető legyen gépünkön. Amennyiben nem az, először telepítsük. Ezután a következő parancssal letölthetjük gépünkre a megfelelő Docker image fájlokat:
x
$ git clone https://github.com/big-data-europe/docker-hadoop.gitA parancs végrehajtása után letöltődnek a szükséges image-ek a docker-hadoop mappába a saját gépünkre. A klaszter elemeit a docker-compose.yml fájl írja le, amennyiben szükséges a klaszter működésének módosítása, úgy ezt a fájlt kell átszerkeszteni. A példánk során mi a módosítatlan konfigurációs fájlt fogjuk használni, ami a következő komponenseket definiálja:
namenode- a Hadoop NameNode csomópont a megfelelő port beállításokkal, ami amasterprimary node szerepét tölti bedatanode- adattároló csomópont, egy darab ( a klaszter egyetlen adat node-ot tartalmaz)resourcemanager- erőforrás kezelésért felelős node (Apache Yarn)nodemanager1- Hadoop Node Manager csomóponthistoryserver- Hadoop history server node
A klaszter elindításához az alábbi Docker parancsot kell kiadnunk:
x
$ docker compose up -dA parancs hatására a megfelelő Docker image-ek letöltődnek a Docker-Hub [4] központi image tárhelyről, lefordulnak és előállnak a szükséges állományok, majd a fenti szolgáltatások elindulnak. A futó szolgáltatásokat és a Hadoop klaszter elemeit az alábbi ábra szemléltet.
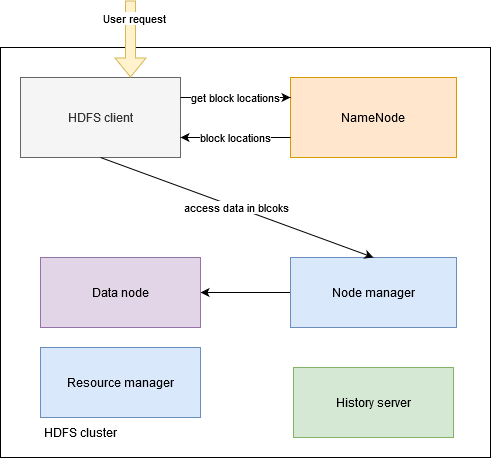
Hadoop klaszter beállításai
Először ellenőrizzük le, hogy a fenti parancs sikeresen végrehajtódott. Adjuk ki az alábbi Docker parancsot:
xxxxxxxxxx$ docker psEz a parancs az éppen futó Docker konténereket listázza ki, így a fenti ábrán is látható öt komponens mindegyikét látnunk kell a listában:

Ha minden rendben van, a NameNode komponenst böngészőből is elérjük a http://localhost:9870 címen. A következő kép a NameNode webes felületét mutatja:
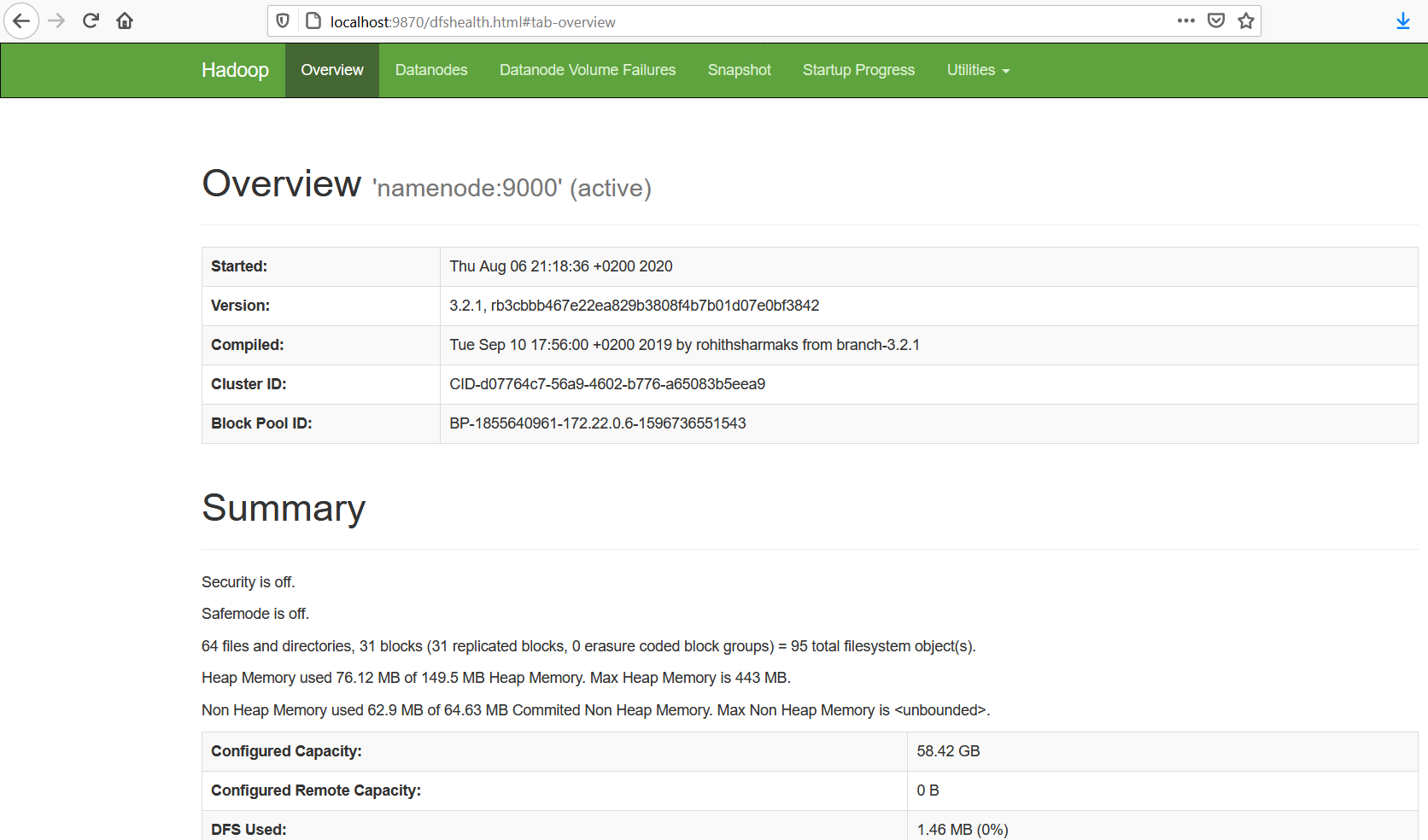
Előfordulhat, hogy a NameNode indulás után ún. safe mode-ba kerül, ekkor a fenti áttekintő oldalon a Safemonde is ON felirat jelenik meg. Ekkor az adat csomópontok nem írhatók, a klasztert nem tudjuk teljes körűen használni. Ebben az esetben a következő lépéseket kell végrehajtanunk.
- Indítsunk egy bash terminált a futó NameNode konténeren belül:
xxxxxxxxxx$ docker exec -it namenode bash- Hagyjuk el a safe mode állapotot a következő parancs kiadásával
xxxxxxxxxxroot@f9f64f9e7eb8:/# hdfs dfsadmin -safemode leave- Töröljünk és állítsunk helyre minden hibás blokkot, amit a safe mode miatti read only mód okozott
xxxxxxxxxxroot@f9f64f9e7eb8:/# hdfs fsck / -deleteEzután töltsük be a NameNode webes felületét, már a fenti Safemode is off feliratot kell látnunk.
Hadoop klaszter tesztelése
Amennyiben fut a Hadoop klaszterünk, a NameNode konténerben futtatott bash terminál segítségével Hadoop parancsokat adhatunk ki a hdfs parancssori kliens segítségével. Ezt az eszközt használhatjuk arra, hogy fájlműveleteket végezzünk a HDFS-en (lásd 2. fejezet). Ehhez lépjünk ismét be a futó NameNode dokcer konténerbe és indítsunk egy bash terminált:
xxxxxxxxxx$ docker exec -it namenode bashHozzunk létre pár egyszerű szöveges fájlt és másoljuk fel őket HDFS-re:
xxxxxxxxxxroot@f9f64f9e7eb8:/# mkdir inputroot@f9f64f9e7eb8:/# echo "Hello World Bye World" >input/file01root@f9f64f9e7eb8:/# echo "Hello Hadoop Goodbye Hadoop" >input/file02Miután a NameNode konténeren belül létrehoztuk a fájlokat, hozzunk létre egy könyvtárat HDFS-en és másoljuk fel ezt a két fájlt:
xxxxxxxxxxroot@f9f64f9e7eb8:/# hadoop fs -mkdir -p /inputroot@f9f64f9e7eb8:/# hdfs dfs -put ./input/* /inputMost már a HDFS-en is elérhető a két fájl, tetszőleges Hadoop kompatibilis eszközzel feldolgozható (pl. MapReduce, Spark, stb.). Listázzuk ki az input könyvtár tartalmát és nézzük meg a fájl tartalmát:
xxxxxxxxxxroot@f9f64f9e7eb8:/# hadoop fs -ls /inputFound 2 items-rw-r--r-- 3 root supergroup 21 2020-08-07 07:56 /input/file01-rw-r--r-- 3 root supergroup 27 2020-08-07 07:56 /input/file02xxxxxxxxxxroot@f9f64f9e7eb8:/# hadoop fs -cat /input/file012020-08-07 11:34:03,619 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = falseHello World Bye WorldA HDFS klaszter leállításához az alábbi Docker parancsot kell használni:
xxxxxxxxxx$ docker compose down 2. fejezet
2. fejezet
Az alábbi videó lecke a HDFS használatát, a rajta végezhető műveleteket demonstrálja:
 További feladatok
További feladatok
- Módosítsuk a Hadoop klaszter konfigurációt úgy, hogy egy data node helyett három induljon!

- Hozz létre egy
feladatmappát a HDFS fájlrendszerben, és másolj fel egy tetszőleges csv fájlt bele, ezután listázd ki a fájlt parancssorból és nézd meg a NameNode webes felületén keresztül is a browser utility segítségével! Ezután pedig töltsd le a csv fájlt HDFS-ről a saját gépre!
Referenciák
[2] https://github.com/big-data-europe/docker-hadoop
[5] https://www.tutorialspoint.com/hadoop/hadoop_command_reference.htm